Overview of the Computing and storage infrastructure
Overview
Teaching: 30 min
Exercises: 15 minQuestions
Where do we run a climate model?
What is a High-Performance Computer?
Where do we store climate model results?
Objectives
NIRD, Notur

An e-infrastructure for Science
E-science is the application of computer technology to the undertaking of modern scientific investigation, including the preparation, experimentation, data collection, results dissemination, and long-term storage and accessibility of all materials generated through the scientific process. These may include data modeling and analysis, electronic/digitized laboratory notebooks, raw and fitted data sets, manuscript production and draft versions, preprints, and print and/or electronic publications.
The e-infrastructure for Science in Norway follows the same structure and provides users with both computing resources (Notur) and post-processing and visualization facilities with large storage capacity (NIRD).
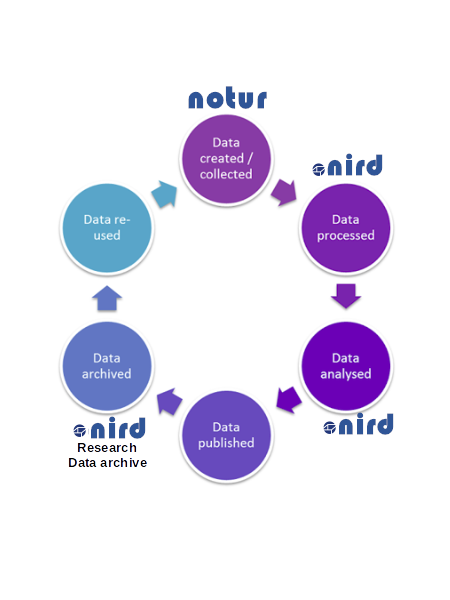
The picture below introduces the data life cycle from the generation of your model outputs on Notur computing facility (Saga) to the preservation of your model results in the NIRD archive.
Notur
What is Notur?
Through the Notur-project, UNINETT Sigma2 serves the Norwegian computational science community by providing the infrastructure to individuals or groups involved in education and research at Norwegian universities and colleges, and research and engineering at research institutes and industry who contribute to the funding of Notur.
The HPC-service provides the customer access to facilities and software with a far greater capacity than is normally available at department and faculty levels. The service is primarily set up to run simulation calculations for research and educations purposes, designed as batches.
For running CESM CAM-6, such computing facilities are necessary.
Saga computing facility

Saga is a cluster machine:
- System: Hewlett Packard Enterprise - Apollo 2000/6500 Gen10
- Number of Cores: 9824
- Number of nodes: 244
- Number of GPUs: 32
- CPU type: * Intel Xeon-Gold 6138 2.0 GHz (normal) * Intel Xeon-Gold 6130 2.1 GHz (bigmem) * Intel Xeon-Gold 6126 2.6 GHz (accel)
- GPU type: NVIDIA P100, 16 GiB RAM (accel)
- Total max floating point performance, double: 645 Teraflop/s (CPUs) + 150 Teraflop/s (GPUs)
- Total memory: 75 TiB
- Total NVMe+SSD local disc: 89 TiB + 60 TiB
- Total parallel filesystem capacity: 1 PB
Saga is a large machine (cluster) made of more than 200 nodes (collection of machines linked together via an efficient network). On one single node, there are 40 cores and a total of 64 GB of shared memory. This shared memory can be accessed by all the processors of one single node but a processor on another node cannot access it. The image below attempts to summarize these two concepts (shared vs. distributed memory):

To manage efficiently the machine, it runs under the control of a batch system. The fact is that one single program does not usually use the full machine (1392 CPUs) but many users can fill the machine very quickly with several “small” programs.
The opposite of a batch job is interactive processing, in which a user enters individual commands to be processed immediately. This is what you are used to when working on your laptop or any UIO servers (such as sverdrup.uio.no).
We need to use a batch system to make sure all the resources are well utilized and this is the role of the job scheduler to decide where to run user “jobs”. Its role is to optimize the resources and to try to run as many user jobs as possible. It can be seen as a tetris game (see image below) where each block represents a user job.

All user jobs must be submitted to the cluster through this batch system. Saga uses SLURM (Portable Batch System). The submitted jobs are then routed into a number of queues (depending on the needed resources, e.g. runtime) and sorted according to some priority scheme.
A job will run when the required resources become available.
More information on the Batch system on Saga can be found here.
Available Filesystems on Saga
The following file systems exist on Saga:
- User area (home directories):
/home
The file system for user home directories on Saga. This file system is currently very small, and it should NOT be used for processing data and running batch jobs (slow access). It has quota enabled, limits can be found here . Files are backed up daily, except for folders called “nobackup” and their sub-folders. - Work area (temporary data):
/cluster/work/users/$USER
Large external storage shared by all compute nodes on Saga. Files are NOT backed up./cluster/workshould be used when running jobs since it’s much larger than/homeand is available on the compute nodes./cluster/work/usersis a parallel file system.
Note: the /cluster/work/users/* directories are subject to automatic deletion dependent on modification, access time and the total usage in the file system. The oldest files will be deleted first.
NIRD
What is NIRD?
NIRD is National e-Infrastructure for Research Data for storing scientific data.
NIRD facility is divided in two parts:
- Active data, which are processed or being analysed, are stored in the Project Area.
- When the data are no longer expected to change and/or results have been published, the data should normally be made accessible to the public. Data can be transferred to the NIRD Archive from the Project area or directly uploaded.
When running the CAM-6 model on Saga, the model outputs are generated and stored in the temporary working area (/cluster/work/users/$USER). As mentioned earlier, the working area on Saga is a temporary storage area and data must be moved to a more permanent storage area where you will be able to easily post-process and visualize your model results.
Model outputs will have to be moved from Saga working area (/cluster/work/users/$USER) to the NIRD project area. You can use scp to copy your data from Saga to NIRD but the detailed procedure will be explained later.
What is a Research Data Archive?
Data archiving is the practice of moving data to a separate storage device that is no longer needed for everyday business operations but may occasionally need to be accessed. Archiving research data facilitates the re-use and verification of research results. By depositing a dataset in a data repository, it is not only protected against corruption and loss, but also becomes findable and citable via a Digital Object Identifier DOI.
This step is very important for publishing scientific results where all data used needs to be kept for about 10 years.
NREC
What is NREC?
NREC means Norwegian Research and Education Cloud and provides researchers from the University of Oslo or Bergen with cloud services.
The NREC cloud is based on OpenStack, which is a large framework of software components used to deliver an Infrastructure-as-a-Service consisting of compute, networking and storage resources.
Post-processing and visualization facility
Once your model run is finished, you can start post-processing and generating plots. The machine you will be using for post-processing and visualizing your data has been created on NREC. The machine will be accessed through a web interface using jupyterhub.
We will be using https://climate.uiogeo-apps.sigma2.no/.
Setup instructions for accessing Jupyter notebooks at Sigma2 server:
- You should have received an email message titled “JupyterHub links for GEO4962”. If not please request it to the course organizers.
- Follow “invitation link” in the email message
- If you don’t already have a Feide guest user account (otherwise skip this step), click “Feide guest users”.
- register a new account (do not use your UiO username as it may be confusing for everyone).
- finish the registration process
- click again on the “invitation link” in the email
- Login with “Feide guest users”
- Accept the different policies
- Agree to become a member of the EScience-Abisko: the browser should display the message “Loading group details”
- Now go to GEO4962 Jupyterhub
- Click “Sign in with Dataporten”
- Login with Feide Guest User (Not your UiO username)
- Finally the web browser should display a page with “jupyterlab” on the upper left side
For later usage of the notebooks just use the GEO4962 Jupyterhub link
The main advantage of using this machine is that your data are directly accessible from anywhere through a web interface and the necessary post-processing and visualization packages we need are already available.
Key Points
Learn about the e-infrastructure we will be using for running and analyzing the model