
Landsat 8 NDVI Analysis on the Cloud
This notebook demonstrates a "Cloud-native" analysis of Normalized Difference Vegetation Index (NDVI) using Landsat 8 data.
What is unique about this workflow is that no data is downloaded to our local computer! All calculations are performed in memory across many distributed machines on the Google Cloud.
This workflow is possible because the Landsat 8 data is stored in Cloud-Optimized Geotiff format, which can be accessed remotely via xarray and rasterio Python libraries. Distributed computing is enabled through a Pangeo JupyterHub deployment with Dask Kubernetes.
About Landsat 8: https://landsat.usgs.gov/landsat-8
About the Landsat archive: https://cloud.google.com/storage/docs/public-datasets/landsat
Date: August 30, 2018
Created by: Scott Henderson (scottyh@uw.edu), Daniel Rothenberg
# Import required libraries
import os
import pandas as pd
import rasterio
import xarray as xr
import requests
from dask.distributed import Client
from dask.distributed import wait, progress
import matplotlib.pyplot as plt
%matplotlib inline
# Print package versions
print('Xarray version: ', xr.__version__)
print('Rasterio version: ', rasterio.__version__)
# Set environment variables for cloud-optimized-geotiffs efficiency
os.environ['GDAL_DISABLE_READDIR_ON_OPEN']='YES'
os.environ['CPL_VSIL_CURL_ALLOWED_EXTENSIONS']='TIF'
Use NASA Common Metadata Repository (CMR) to get Landsat 8 images
NASA CMR is a new unified way to search for remote sensing assests across many archive centers. If you prefer a graphical user interface, NASA Earthdata Search is built on top of CMR. CMR returns download links through the USGS (https://earthexplorer.usgs.gov), but the same archive is mirrored as a (Google Public Dataset)[https://cloud.google.com/storage/docs/public-datasets/landsat], so we'll make a function that queries CMR and returns URLs to the imagery stored on Google Cloud.
def query_cmr_landsat(collection='Landsat_8_OLI_TIRS_C1',tier='T1', path=47, row=27):
"""Query NASA CMR for Collection1, Tier1 Landsat scenes from a specific path and row."""
data = [f'short_name={collection}',
f'page_size=2000',
f'attribute[]=string,CollectionCategory,{tier}',
f'attribute[]=int,WRSPath,{path}',
f'attribute[]=int,WRSRow,{row}',
]
query = 'https://cmr.earthdata.nasa.gov/search/granules.json?' + '&'.join(data)
r = requests.get(query, timeout=100)
print(r.url)
df = pd.DataFrame(r.json()['feed']['entry'])
# Save results to a file
#print('Saved results to cmr-result.json')
#with open('cmr-result.json', 'w') as j:
# j.write(r.text)
return df
def make_google_archive(pids, bands):
"""Turn list of product_ids into pandas dataframe for NDVI analysis."""
path = pids[0].split('_')[2][1:3]
row = pids[0].split('_')[2][-2:]
baseurl = f'https://storage.googleapis.com/gcp-public-data-landsat/LC08/01/0{path}/0{row}'
dates = [pd.to_datetime(x.split('_')[3]) for x in pids]
df = pd.DataFrame(dict(product_id=pids, date=dates))
for band in bands:
df[band] = [f'{baseurl}/{x}/{x}_{band}.TIF' for x in pids]
return df
df = query_cmr_landsat()
pids = df.title.tolist()
df = make_google_archive(pids, ['B4', 'B5'])
df.head()
# Select 10 'workers' under 'manual scaling' menu below and click 'Scale'
# Click on the 'Dashboard link' to monitor calculation progress
from dask.distributed import Client
client = Client(n_workers=10, threads_per_worker=2, memory_limit='60GB')
Examine a single band Landsat image
The rasterio library allows us to read Geotiffs on the web without downloading the entire image. Xarray has a built-in load_rasterio() function that allows us to open the file as a DataArray. Xarray also uses Dask for lazy reading, so we want to make sure the native block tiling of the image matches the dask "chunk size". These dask chunks are automatically distributed among all our workers when a computation is requested, so ideally they will fit in the worker memory. A chunk size of 2048x2048 with a float32 datatype implies a 16Mb array.
# Load with rasterio
image_url = df.iloc[0]['B4']
with rasterio.open(image_url) as src:
print(src.profile)
# Note that the blocksize of the image is 256 by 256, so we want xarray to use some multiple of that
xchunk = 2048
ychunk = 2048
da = xr.open_rasterio(image_url, chunks={'band': 1, 'x': xchunk, 'y': ychunk})
da
# If we request to compute something or plot these arrays, the necessary data chunks will be accessed on cloud storage:
# Watch the KubeCluster dashboard to see the worker activity when this command is run:
# Note that no data is stored on the disk here, it's all in memory
da.sel(band=1).plot.imshow()

Load all Landsat bands into an xarray dataset
Often we want to analyze a time series of satellite imagery, but we are constrained by computational resources. So we either download all the images, extract a small subset and then do our analysis. Or, we coarsen the resolution of all our images so that the entire set fits into our computer RAM. Because this notebook is running on Google Cloud with access to many resources in our Kube Cluster, we no longer have to worry about the computational constraints, and can conduct our analysis at full resoution!
First we need to construct an xarray dataset object (which has data variables 'band4' and 'band5' in a n-dimensional array with x-coordinates representing UTM easting, y-coordinates representing UTM northing, and a time coordinate representing the image acquisition date).
There are different ways to go about this, but we will load our images with a timestamp index since each image is taken on a different date. Typically, this is a chore if our images are not on the same grid to begin with, but xarray knows how to automatically align images based on their georeferenced coordinates.
# Note that these landsat images are not necessarily the same shape or on the same grid:
for image_url in df.B4[:5]:
with rasterio.open(image_url) as src:
print(src.shape, src.bounds)
def create_multiband_dataset(row, bands=['B4','B5'], chunks={'band': 1, 'x': 2048, 'y': 2048}):
'''A function to load multiple landsat bands into an xarray dataset '''
# Each image is a dataset containing both band4 and band5
datasets = []
for band in bands:
url = row[band]
da = xr.open_rasterio(url, chunks=chunks)
da = da.squeeze().drop(labels='band')
ds = da.to_dataset(name=band)
datasets.append(ds)
DS = xr.merge(datasets)
return DS
# Merge all acquisitions into a single large Dataset
datasets = []
for i,row in df.iterrows():
try:
print('loading...', row.date)
ds = create_multiband_dataset(row)
datasets.append(ds)
except Exception as e:
print('ERROR loading, skipping acquistion!')
print(e)
DS = xr.concat(datasets, dim=pd.DatetimeIndex(df.date.tolist(), name='time'))
print('Dataset size (Gb): ', DS.nbytes/1e9)
DS
Note that xarray has automatically expanded the dimensions to include the maximum extents of all the images, also the chunksize has been automatically adjusted.
There is definitely some room for improvement here from a computational efficiency standpoint - in particular the dask chunks are no longer aligned with the image tiles. This is because each image starts at different coordinates and has different shapes, but xarray uses a single chunk size for the entire datasets. There will also be many zeros in this dataset, so future work could take advantage of sparse arrays.
These points aside, our KubeCluster will automatically parallelize our computations for us, so we can not worry too much about optimal efficiency and just go ahead and run our analysis!
# Here is the syntax to plot the same image as before
# Again, the actually image data is downloaded from cloud storage to memory
da = DS.sel(time='2013-04-21')['B4']
print('Image size (Gb): ', da.nbytes/1e9)
da.plot.imshow()

NDVI = (DS['B5'] - DS['B4']) / (DS['B5'] + DS['B4'])
NDVI
NDVI.sel(time='2013-04-21').plot.imshow()

ndvi = NDVI.sel(time=slice('2013-01-01', '2014-01-01')).mean(dim='time').persist()
print('projected dataset size (Gb): ', ndvi.nbytes/1e9)
print(ndvi)
ndvi.plot.imshow()
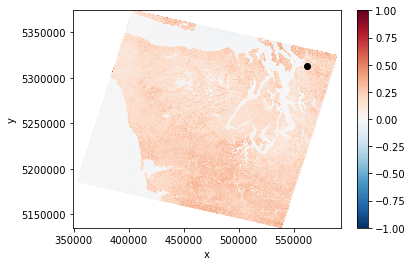
# Point of interest we'll extract a timeseries from
plt.plot(562370, 5312519, 'ko')
# https://www.geoplaner.com
# lat, lon to northing, easting
# 47.962940 --> 5312519
# -122.164483--> 562370
#+ 5 km buffer
#EPSG:32610 WGS 84 / UTM zone 10N
xcen = 562370
ycen = 5312519
buf = 5000 # look at point +/- 5km
ds = NDVI.sel(x=slice(xcen-buf,xcen+buf), y=slice(ycen-buf,ycen+buf))
timeseries = ds.resample(time='1MS').mean().persist()
timeseries
# select nearest point and plot timeserie
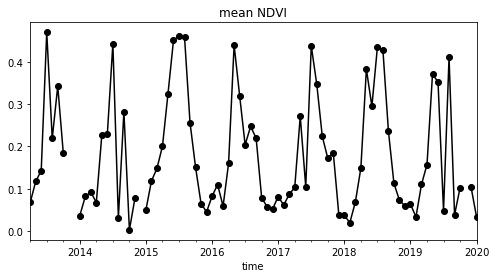
s = timeseries.sel(x=xcen, y=ycen, method="nearest").to_series()
s.plot(title='mean NDVI', figsize=(8,4), style='ko-')
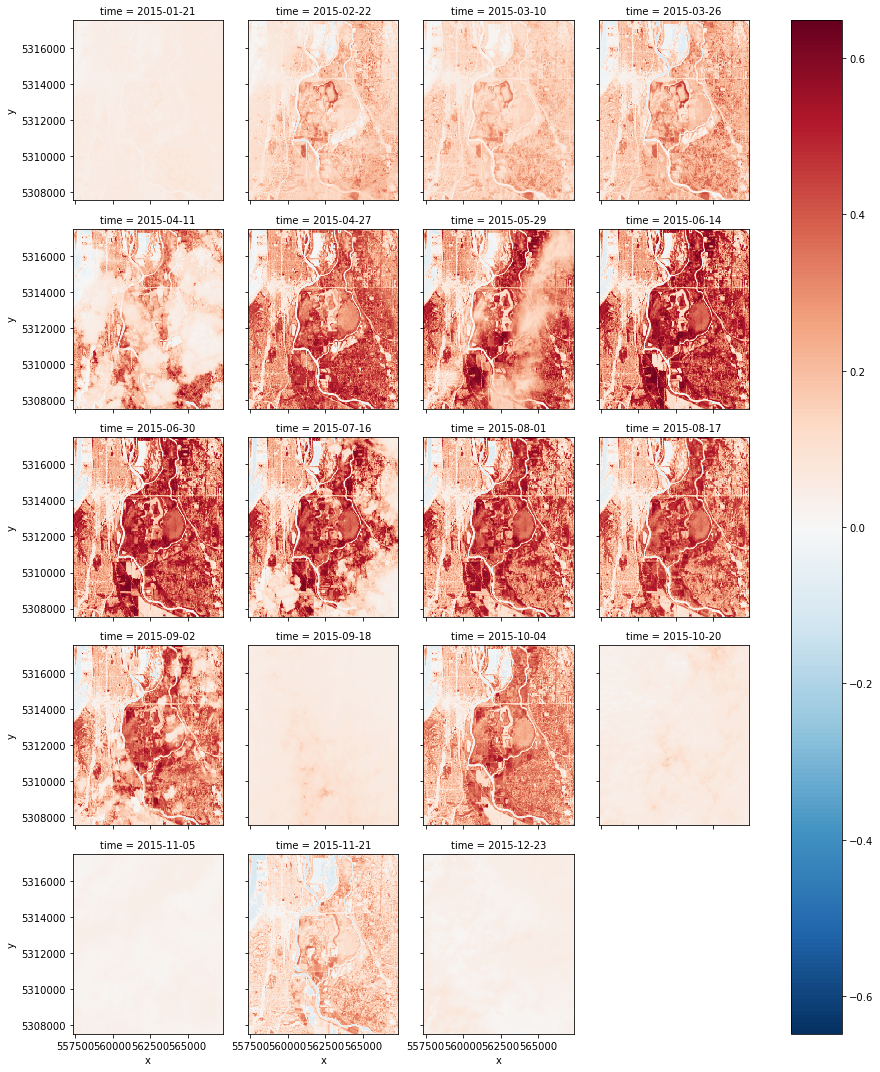
ds.sel(time=slice('2015-01-01', '2016-01-01')).plot.imshow('x', 'y', col='time', col_wrap=4)
In conclusion
- This notebook demonstrates the power of storing data publically in the Cloud as optimized geotiffs - scientists can conduct scalable analysis without downloading the data to a local machine. Only derived subsets and figures need to be downloaded!
- We used a crude NDVI calculation, designed to demonstrate the syntax and tools - a proper analysis should take into account cloud masks and other corrections
client.shutdown()