
RATECE-PLANICA ski station (Slovenia) under CMIP-6 SSP585 conditio
RATECE-PLANICA ski station (Slovenia) under CMIP-6 SSP585 condition
- Description: SSP-based RCP scenario with high radiative forcing by the end of century. Following approximately RCP8.5 global forcing pathway with SSP5 socioeconomic conditions. Concentration-driven.
- Rationale: the scenario represents the high end of plausible future pathways. SSP5 is the only SSP with emissions high enough to produce the 8.5 W/m2 level of forcing in 2100.
- Full description on ES-DOC
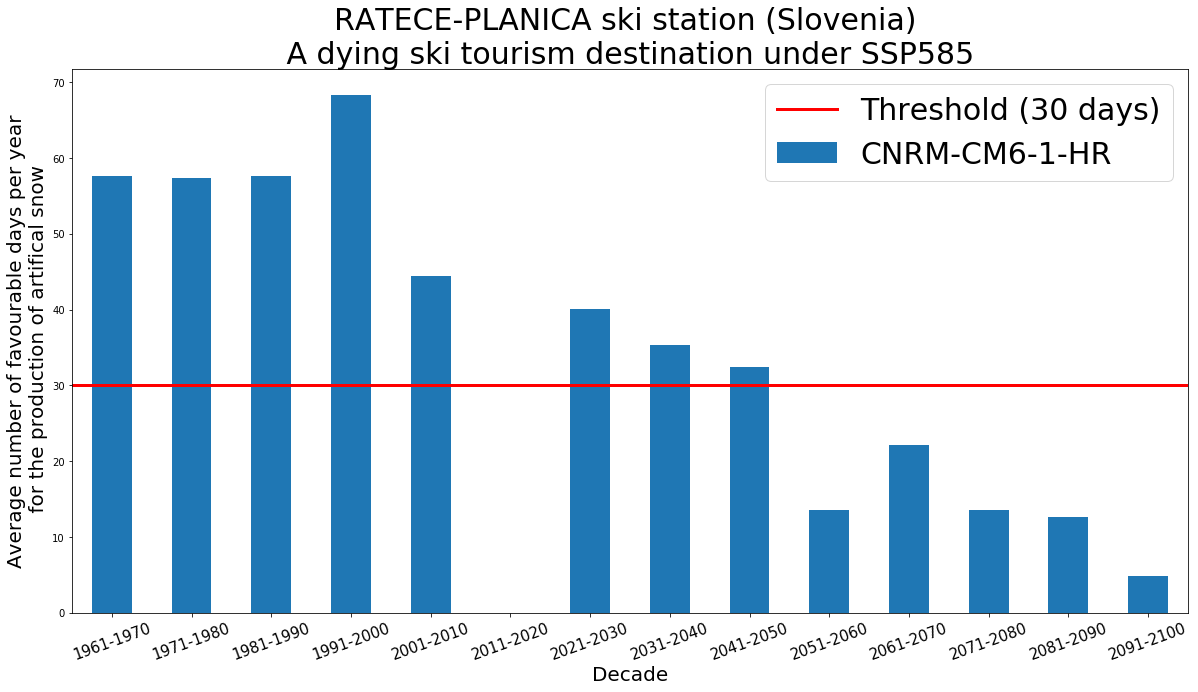
Is it worth investing in artificial snowmaking equipment at RATECE-PLANICA?
from ipyleaflet import Map, Marker, basemaps
center = (46.5, 13.70)
m = Map(
basemap=basemaps.OpenTopoMap,
center=center,
zoom=7
)
marker = Marker(location=center, draggable=False)
m.add_layer(marker);
m
import xarray as xr
import pandas as pd
import cftime
import intake
from dask.distributed import Client
from dask.distributed import wait, progress
xr.set_options(display_style='html')
%matplotlib inline
filename = 'http://berkeleyearth.lbl.gov/auto/Stations/TAVG/Text/22498-TAVG-Data.txt'
data = pd.read_csv(filename, sep='\s+', header=None, comment='%')
mean_st_1961_2005 = data[(data[0] >= 1961 ) & (data[0] <= 2005)][6].mean()
std_st_1961_2005 = data[(data[0] >= 1961 ) & (data[0] <= 2005)][6].std()
print(mean_st_1961_2005 + 273.15, std_st_1961_2005)
# list of values
lst = [mean_st_1961_2005 + 273.15, std_st_1961_2005]
# Calling DataFrame constructor on list
# with indices and columns specified
df_st = pd.DataFrame(lst, index =['mean', 'stddev'],
columns =['RATECE-PLANICA-T2M-1961-2005'])
df_st.to_csv('RATECE-PLANICA-1961-2005_t2m.csv')
df_st
col_url = "https://raw.githubusercontent.com/NCAR/intake-esm-datastore/master/catalogs/pangeo-cmip6.json"
col = intake.open_esm_datastore(col_url)
cat = col.search(experiment_id=['historical', 'ssp585'], table_id='day',
variable_id=['tas', 'tasmin', 'tasmax'], source_id='CNRM-CM6-1-HR', institution_id='CNRM-CERFACS')
cat.df
dset_dict = cat.to_dataset_dict(zarr_kwargs={'consolidated': True})
list(dset_dict.keys())
# Select 10 'workers' under 'manual scaling' menu below and click 'Scale'
# Click on the 'Dashboard link' to monitor calculation progress
from dask.distributed import Client
client = Client(n_workers=10, threads_per_worker=2, memory_limit='60GB')
ds_hist = dset_dict['CMIP.CNRM-CERFACS.CNRM-CM6-1-HR.historical.day.gr']
ds_hist
p = ds_hist['tas'].sel(time=slice(pd.datetime(1961, 1, 1), pd.datetime(2005, 12, 31))).sel(lat=46.5,lon=13.7, method="nearest")
p
mean_cmip6_1961_2005 = p.mean().values
std_cmip6_1961_2005 = p.std().values
print(mean_cmip6_1961_2005, std_cmip6_1961_2005)
# list of values
lst = [mean_cmip6_1961_2005, std_cmip6_1961_2005]
# Calling DataFrame constructor on list
# with indices and columns specified
df_cmip6 = pd.DataFrame(lst, index =['mean', 'stddev'],
columns =['RATECE-PLANICA-T2M-1961-2005'])
df_cmip6.to_csv('RATECE-PLANICA-1961-2005_t2m_cmip6.csv')
df_cmip6
p = ds_hist['tasmin'].sel(time=slice(pd.datetime(1961, 1, 1), pd.datetime(2010, 12, 31))).sel(lat=46.5,lon=13.7, method="nearest")
t2min_h_bias_corrected = (p - mean_cmip6_1961_2005)/std_cmip6_1961_2005 * std_st_1961_2005 + mean_st_1961_2005
t2min_h_bias_corrected
p = ds_hist['tasmax'].sel(time=slice(pd.datetime(1961, 1, 1), pd.datetime(2010, 12, 31))).sel(lat=46.5,lon=13.7, method="nearest")
t2max_h_bias_corrected = (p - mean_cmip6_1961_2005)/std_cmip6_1961_2005 * std_st_1961_2005 + mean_st_1961_2005
t2max_h_bias_corrected
ds_ssp585 = dset_dict['ScenarioMIP.CNRM-CERFACS.CNRM-CM6-1-HR.ssp585.day.gr']
ds_ssp585
p = ds_ssp585['tasmin'].sel(time=slice(pd.datetime(2021, 1, 1), pd.datetime(2100, 12, 31))).sel(lat=46.5,lon=13.7, method="nearest")
t2min_p_bias_corrected = (p - mean_cmip6_1961_2005)/std_cmip6_1961_2005 * std_st_1961_2005 + mean_st_1961_2005
t2min_p_bias_corrected
p = ds_ssp585['tasmax'].sel(time=slice(pd.datetime(2021, 1, 1), pd.datetime(2100, 12, 31))).sel(lat=46.5,lon=13.7, method="nearest")
t2max_p_bias_corrected = (p - mean_cmip6_1961_2005)/std_cmip6_1961_2005 * std_st_1961_2005 + mean_st_1961_2005
t2max_p_bias_corrected
nb_favourable_h = t2min_h_bias_corrected.where((t2min_h_bias_corrected < 0) & (t2max_h_bias_corrected <= 3)).groupby('time.year').count()
nb_favourable_h
nb_favourable_p = t2min_p_bias_corrected.where((t2min_p_bias_corrected < 0) & (t2max_p_bias_corrected <= 3)).groupby('time.year').count()
nb_favourable_p
nb_favourable = xr.merge([nb_favourable_h, nb_favourable_p])
nb_favourable
series = nb_favourable.tasmin.to_series()
series = series.reset_index(level='member_id').drop(columns=['member_id'])
series.index = pd.to_datetime(series.index, format='%Y')
series
series.to_csv("nb_favourable_snow_cmip6.csv")
series10YS = series.groupby(pd.Grouper(freq='10YS')).mean()
import matplotlib.pyplot as plt
from datetime import datetime
from datetime import timedelta
from dateutil.relativedelta import relativedelta
fig = plt.figure(1, figsize=[20,10])
ax = plt.subplot(1, 1, 1)
series10YS.plot.bar(ax=ax)
plt.axhline(y=30, color='r', linestyle='-', linewidth=3)
labels = [datetime.strptime(item.get_text(), '%Y-%m-%d %H:%M:%S').strftime("%Y") + '-' +
(datetime.strptime(item.get_text() , '%Y-%m-%d %H:%M:%S') + relativedelta(years=9)).strftime("%Y") for item in ax.get_xticklabels()]
ax.set_xticklabels(labels, rotation=20, fontsize = 15)
ax.set_xlabel('Decade', fontsize = 20)
ax.set_ylabel('Average number of favourable days per year\n for the production of artifical snow', fontsize = 20)
plt.title("RATECE-PLANICA ski station (Slovenia) \n A dying ski tourism destination under SSP585 ", fontsize=30)
ax.legend(labels=['Threshold (30 days)','CNRM-CM6-1-HR'], fontsize=30)
plt.savefig("nb_favourable_snow_cmip6.png")
client.shutdown()