Analyzing Tabular Data
Overview
Teaching: 60 min
Exercises: 30 minQuestions
How can I process tabular data files in Python?
Objectives
Explain what a library is and what libraries are used for.
Import a Python library and use the functions it contains.
Read tabular data from a file into a program.
Assign values to variables.
Select individual values and subsections from data.
Perform operations on arrays of data.
Plot simple graphs from data.
The best way to learn how to program is to do something useful, so this introduction to Python is built around a common scientific task: data analysis.
Prerequisites
You need to understand the concepts of files and directories and how to start a Python interpreter before tackling this lesson. This lesson sometimes references Jupyter Notebook although you can use any Python interpreter mentioned in the Setup.
The commands in this lesson pertain to Python 3.
Temperature anomalies in Polar regions: Arctic and Antarctic
In this episode we will learn how to work with datasets from Climate4you containing Temperature anomalies in Polar regions. The main objective of Climate4you is to provide information on meteorological and climatologically issues of general and specific interest. The dataset that has been prepared for this lesson contains comma-separted values (CSV) series of UAH MSU global monthly lower troposphere temperature anomalies since December 1978. The reference period for computing the temperature anomalies is 1981-2010.
- each row holds temperature anomalies for a single date (year and month), starting from December 1978.
- columns represents different geographical areas
Data were split by decade so we have several files covering the period between December 1978 to February 2019.
The first five rows of our first file look like this:
Globe,Land,Ocean,NH,Land,Ocean,SH,Land,Ocean,Trpcs,Land,Ocean,NoExt,Land,Ocean,SoExt,Land,Ocean,NoPol,Land,Ocean,SoPol,Land,Ocean,USA48,USA49,AUST -0.28,-0.36,-0.24,-0.30,-0.41,-0.20,-0.26,-0.27,-0.26,-0.21,-0.22,-0.21,-0.37,-0.51,-0.20,-0.26,-0.21,-0.28,-0.61,-1.29,0.47,-0.20,-0.20,-0.21,-1.60,-1.46,-0.50 -0.25,-0.40,-0.17,-0.47,-0.69,-0.26,-0.03,0.17,-0.10,-0.12,-0.11,-0.13,-0.67,-0.88,-0.40,0.03,0.41,-0.07,-0.45,-1.03,0.46,0.25,0.43,0.10,-3.75,-2.77,1.22 -0.26,-0.46,-0.14,-0.42,-0.57,-0.26,-0.10,-0.24,-0.05,0.00,0.07,-0.03,-0.65,-0.82,-0.43,-0.13,-0.39,-0.06,-2.86,-3.15,-2.39,-0.31,-0.68,-0.01,-2.41,-2.48,-0.17 -0.26,-0.34,-0.21,-0.35,-0.36,-0.34,-0.17,-0.30,-0.13,-0.10,-0.15,-0.08,-0.51,-0.46,-0.57,-0.17,-0.31,-0.13,-0.94,-1.14,-0.63,-0.41,-0.89,-0.03,-0.52,-0.34,0.32Data were obtained by the National Oceanographic and Atmospheric Administration (NOAA) TIROS-N satellite, interpreted by Dr. Roy Spencer and Dr. John Christy, both at Global Hydrology and Climate Center, University of Alabama at Huntsville, USA.
So, we want to:
- Calculate the average temperature per geographical areas across all dates.
- Plot the result to discuss and share with colleagues.
To do all that, we’ll have to learn a little bit about programming.
Before we discuss how to deal with many data points, let’s learn how to work with single data values.
Variables
Any Python interpreter can be used as a calculator:
3 + 5 * 4
23
This is great but not very interesting.
To do anything useful with data, we need to assign its value to a variable.
In Python, we can assign a value to a
variable, using the equals sign =.
For example, to assign value 60 to a variable weight_kg, we would execute:
weight_kg = 60
From now on, whenever we use weight_kg, Python will substitute the value we assigned to
it. In essence, a variable is just a name for a value.
In Python, variable names:
- can include letters, digits, and underscores
- cannot start with a digit
- are case sensitive.
This means that, for example:
weight0is a valid variable name, whereas0weightis notweightandWeightare different variables
Types of data
Python knows various types of data. Three common ones are:
- integer numbers
- floating point numbers, and
- strings.
In the example above, variable weight_kg has an integer value of 60.
To create a variable with a floating point value, we can execute:
weight_kg = 60.0
And to create a string we simply have to add single or double quotes around some text, for example:
weight_kg_text = 'weight in kilograms:'
Using Variables in Python
To display the value of a variable to the screen in Python, we can use the print function:
print(weight_kg)
60.0
We can display multiple things at once using only one print command:
print(weight_kg_text, weight_kg)
weight in kilograms: 60.0
Moreover, we can do arithmetics with variables right inside the print function:
print('weight in pounds:', 2.2 * weight_kg)
weight in pounds: 132.0
The above command, however, did not change the value of weight_kg:
print(weight_kg)
60.0
To change the value of the weight_kg variable, we have to
assign weight_kg a new value using the equals = sign:
weight_kg = 65.0
print('weight in kilograms is now:', weight_kg)
weight in kilograms is now: 65.0
Variables as Sticky Notes
A variable is analogous to a sticky note with a name written on it: assigning a value to a variable is like putting that sticky note on a particular value.
This means that assigning a value to one variable does not change values of other variables. For example, let’s store the subject’s weight in pounds in its own variable:
# There are 2.2 pounds per kilogram weight_lb = 2.2 * weight_kg print(weight_kg_text, weight_kg, 'and in pounds:', weight_lb)weight in kilograms: 65.0 and in pounds: 143.0
Let’s now change
weight_kg:weight_kg = 100.0 print('weight in kilograms is now:', weight_kg, 'and weight in pounds is still:', weight_lb)weight in kilograms is now: 100.0 and weight in pounds is still: 143.0
Since
weight_lbdoesn’t “remember” where its value comes from, it is not updated when we changeweight_kg.



Words are useful, but what’s more useful are the sentences and stories we build with them. Similarly, while a lot of powerful, general tools are built into Python, specialized tools built up from these basic units live in libraries that can be called upon when needed.
Loading data into Python
In order to load our temperature data series, we need to access (import in Python terminology) a library called NumPy. In general you should use this library if you want to do fancy things with numbers, especially if you have matrices or arrays. We can import NumPy using:
import numpy
Importing a library is like getting a piece of lab equipment out of a storage locker and setting it up on the bench. Libraries provide additional functionality to the basic Python package, much like a new piece of equipment adds functionality to a lab space. Just like in the lab, importing too many libraries can sometimes complicate and slow down your programs - so we only import what we need for each program. Once we’ve imported the library, we can ask the library to read our data file for us:
numpy.loadtxt(fname='uahncdc.lt-01.csv', skiprows=1, delimiter=',')
array([[-0.28, -0.36, -0.24, -0.3 , -0.41, -0.2 , -0.26, -0.27, -0.26,
-0.21, -0.22, -0.21, -0.37, -0.51, -0.2 , -0.26, -0.21, -0.28,
-0.61, -1.29, 0.47, -0.2 , -0.2 , -0.21, -1.6 , -1.46, -0.5 ],
[-0.25, -0.4 , -0.17, -0.47, -0.69, -0.26, -0.03, 0.17, -0.1 ,
-0.12, -0.11, -0.13, -0.67, -0.88, -0.4 , 0.03, 0.41, -0.07,
-0.45, -1.03, 0.46, 0.25, 0.43, 0.1 , -3.75, -2.77, 1.22],
[-0.26, -0.46, -0.14, -0.42, -0.57, -0.26, -0.1 , -0.24, -0.05,
0. , 0.07, -0.03, -0.65, -0.82, -0.43, -0.13, -0.39, -0.06,
-2.86, -3.15, -2.39, -0.31, -0.68, -0.01, -2.41, -2.48, -0.17],
...
[ 0.02, 0.21, -0.09, -0.03, 0.12, -0.17, 0.07, 0.37, -0.03,
-0.02, -0.15, 0.05, -0.02, 0.23, -0.33, 0.1 , 0.75, -0.08,
-1.07, -0.64, -1.74, 1.34, 1.51, 1.21, 1.66, 0.72, 0.41]])
The expression numpy.loadtxt(...) is a function call
that asks Python to run the function loadtxt which
belongs to the numpy library. This dotted notation
is used everywhere in Python: the thing that appears before the dot contains the thing that
appears after.
As an example, John Smith is the John that belongs to the Smith family.
We could use the dot notation to write his name smith.john,
just as loadtxt is a function that belongs to the numpy library.
numpy.loadtxt has three parameters: the name of the file
we want to read, the number of initial rows to skip (header containing the names of each column)
and the delimiter that separates values on
a line. These parameters need to be character strings (or strings
for short), so we put them in quotes.
Since we haven’t told it to do anything else with the function’s output,
the notebook displays it.
In this case,
that output is the data we just loaded.
By default,
only a few rows and columns are shown
(with ... to omit elements when displaying big arrays).
To save space,
Python displays numbers as 1. instead of 1.0
when there’s nothing interesting after the decimal point.
Our call to numpy.loadtxt read our file
but didn’t save the data in memory.
To do that,
we need to assign the array to a variable. Just as we can assign a single value to a variable, we
can also assign an array of values to a variable using the same syntax. Let’s re-run
numpy.loadtxt and save the returned data:
data = numpy.loadtxt(fname='uahncdc.lt-01.csv', skiprows=1, delimiter=',')
This statement doesn’t produce any output because we’ve assigned the output to the variable data.
If we want to check that the data have been loaded,
we can print the variable’s value:
print(data)
[[-0.28, -0.36, -0.24, -0.3 , -0.41, -0.2 , -0.26, -0.27, -0.26,
-0.21, -0.22, -0.21, -0.37, -0.51, -0.2 , -0.26, -0.21, -0.28,
-0.61, -1.29, 0.47, -0.2 , -0.2 , -0.21, -1.6 , -1.46, -0.5 ],
[-0.25, -0.4 , -0.17, -0.47, -0.69, -0.26, -0.03, 0.17, -0.1 ,
-0.12, -0.11, -0.13, -0.67, -0.88, -0.4 , 0.03, 0.41, -0.07,
-0.45, -1.03, 0.46, 0.25, 0.43, 0.1 , -3.75, -2.77, 1.22],
[-0.26, -0.46, -0.14, -0.42, -0.57, -0.26, -0.1 , -0.24, -0.05,
0. , 0.07, -0.03, -0.65, -0.82, -0.43, -0.13, -0.39, -0.06,
-2.86, -3.15, -2.39, -0.31, -0.68, -0.01, -2.41, -2.48, -0.17],
...
[ 0.02, 0.21, -0.09, -0.03, 0.12, -0.17, 0.07, 0.37, -0.03,
-0.02, -0.15, 0.05, -0.02, 0.23, -0.33, 0.1 , 0.75, -0.08,
-1.07, -0.64, -1.74, 1.34, 1.51, 1.21, 1.66, 0.72, 0.41]]
Now that the data are in memory,
we can manipulate them.
First,
let’s ask what type of thing data refers to:
print(type(data))
<class 'numpy.ndarray'>
The output tells us that data currently refers to
an N-dimensional array, the functionality for which is provided by the NumPy library.
These data correspond to temperature anomalies (degree Celcius) over various geographical regions.
The rows are measurements at different dates, and the columns
are their corresponding temperature anomalies.
Data Type
A Numpy array contains one or more elements of the same type. The
typefunction will only tell you that a variable is a NumPy array but won’t tell you the type of thing inside the array. We can find out the type of the data contained in the NumPy array.print(data.dtype)dtype('float64')This tells us that the NumPy array’s elements are floating-point numbers.
With the following command, we can see the array’s shape:
print(data.shape)
(13, 27)
The output tells us that the data array variable contains 13 rows and 27 columns. When we
created the variable data to store our data, we didn’t just create the array; we also
created information about the array, called members or
attributes. This extra information describes data in the same way an adjective describes a noun.
data.shape is an attribute of data which describes the dimensions of data. We use the same
dotted notation for the attributes of variables that we use for the functions in libraries because
they have the same part-and-whole relationship.
If we want to get a single number from the array, we must provide an index in square brackets after the variable name, just as we do in math when referring to an element of a matrix. Our data has two dimensions, so we will need to use two indices to refer to one specific value:
print('first value in data:', data[0, 0])
first value in data: -0.28
print('middle value in data:', data[6, 14])
middle value in data: -0.32
The expression data[6, 14] accesses the element at row 6, column 14. While this expression may
The expression data[6, 14] accesses the element at row 6, column 14. While this expression may
not surprise you,
data[0, 0] might.
Programming languages like Fortran, MATLAB and R start counting at 1
because that’s what human beings have done for thousands of years.
Languages in the C family (including C++, Java, Perl, and Python) count from 0
because it represents an offset from the first value in the array (the second
value is offset by one index from the first value). This is closer to the way
that computers represent arrays (if you are interested in the historical
reasons behind counting indices from zero, you can read
Mike Hoye’s blog post).
As a result,
if we have an M×N array in Python,
its indices go from 0 to M-1 on the first axis
and 0 to N-1 on the second.
It takes a bit of getting used to,
but one way to remember the rule is that
the index is how many steps we have to take from the start to get the item we want.
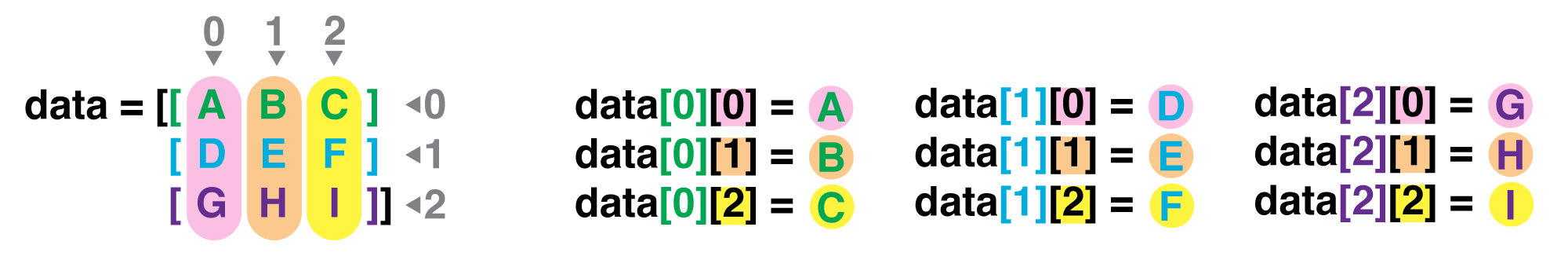
In the Corner
What may also surprise you is that when Python displays an array, it shows the element with index
[0, 0]in the upper left corner rather than the lower left. This is consistent with the way mathematicians draw matrices but different from the Cartesian coordinates. The indices are (row, column) instead of (column, row) for the same reason, which can be confusing when plotting data.
Slicing data
An index like [6, 14] selects a single element of an array,
but we can select whole sections as well.
For example,
we can select the first ten days (columns) of values
for the first four patients (rows) like this:
print(data[0:4, 0:10])
[[-0.28 -0.36 -0.24 -0.3 -0.41 -0.2 -0.26 -0.27 -0.26 -0.21]
[-0.25 -0.4 -0.17 -0.47 -0.69 -0.26 -0.03 0.17 -0.1 -0.12]
[-0.26 -0.46 -0.14 -0.42 -0.57 -0.26 -0.1 -0.24 -0.05 0. ]
[-0.26 -0.34 -0.21 -0.35 -0.36 -0.34 -0.17 -0.3 -0.13 -0.1 ]]
The slice 0:4 means, “Start at index 0 and go up to, but not
including, index 4”. Again, the up-to-but-not-including takes a bit of getting used to, but the
rule is that the difference between the upper and lower bounds is the number of values in the slice.
We don’t have to start slices at 0:
print(data[5:10, 0:10])
[[-0.25 -0.35 -0.19 -0.38 -0.37 -0.38 -0.11 -0.29 -0.05 -0.12]
[-0.2 -0.26 -0.17 -0.26 -0.29 -0.22 -0.15 -0.19 -0.14 -0.06]
[-0.12 -0.28 -0.03 -0. -0.16 0.15 -0.24 -0.51 -0.15 0. ]
[-0.24 -0.34 -0.18 -0.19 -0.29 -0.09 -0.29 -0.42 -0.24 -0.01]
[-0.1 -0.16 -0.06 -0.14 -0.14 -0.15 -0.06 -0.21 -0. 0.03]]
We also don’t have to include the upper and lower bound on the slice. If we don’t include the lower bound, Python uses 0 by default; if we don’t include the upper, the slice runs to the end of the axis, and if we don’t include either (i.e., if we just use ‘:’ on its own), the slice includes everything:
small = data[:3, 20:]
print('small is:')
print(small)
The above example selects rows 0 through 2 and columns 20 through to the end of the array.
small is:
[[ 0.47 -0.2 -0.2 -0.21 -1.6 -1.46 -0.5 ]
[ 0.46 0.25 0.43 0.1 -3.75 -2.77 1.22]
[-2.39 -0.31 -0.68 -0.01 -2.41 -2.48 -0.17]]
Arrays also know how to perform common mathematical operations on their values. The simplest operations with data are arithmetic: addition, subtraction, multiplication, and division. When you do such operations on arrays, the operation is done element-by-element. Thus:
doubledata = data * 2.0
will create a new array doubledata
each element of which is twice the value of the corresponding element in data:
print('original:')
print(data[:3, 20:])
print('doubledata:')
print(doubledata[:3, 20:])
original:
[[ 0.47 -0.2 -0.2 -0.21 -1.6 -1.46 -0.5 ]
[ 0.46 0.25 0.43 0.1 -3.75 -2.77 1.22]
[-2.39 -0.31 -0.68 -0.01 -2.41 -2.48 -0.17]]
doubledata:
[[ 0.94 -0.4 -0.4 -0.42 -3.2 -2.92 -1. ]
[ 0.92 0.5 0.86 0.2 -7.5 -5.54 2.44]
[-4.78 -0.62 -1.36 -0.02 -4.82 -4.96 -0.34]]
If, instead of taking an array and doing arithmetic with a single value (as above), you did the arithmetic operation with another array of the same shape, the operation will be done on corresponding elements of the two arrays. Thus:
tripledata = doubledata + data
will give you an array where tripledata[0,0] will equal doubledata[0,0] plus data[0,0],
and so on for all other elements of the arrays.
print('tripledata:')
print(tripledata[:3, 20:])
tripledata:
[[ 1.41 -0.6 -0.6 -0.63 -4.8 -4.38 -1.5 ]
[ 1.38 0.75 1.29 0.3 -11.25 -8.31 3.66]
[ -7.17 -0.93 -2.04 -0.03 -7.23 -7.44 -0.51]]
Often, we want to do more than add, subtract, multiply, and divide array elements. NumPy knows how
to do more complex operations, too. If we want to find the average temperature anomalies for all dates on
all geographical regions, for example, we can ask NumPy to compute data’s mean value:
print(numpy.mean(data))
-0.28806267806267805
mean is a function that takes
an array as an argument.
Not All Functions Have Input
Generally, a function uses inputs to produce outputs. However, some functions produce outputs without needing any input. For example, checking the current time doesn’t require any input.
import time print(time.ctime())'Sat Mar 26 13:07:33 2016'For functions that don’t take in any arguments, we still need parentheses (
()) to tell Python to go and do something for us.
NumPy has lots of useful functions that take an array as input. Let’s use three of those functions to get some descriptive values about the dataset. We’ll also use multiple assignment, a convenient Python feature that will enable us to do this all in one line.
maxval, minval, stdval = numpy.max(data), numpy.min(data), numpy.std(data)
print('maximum temperature anomaly:', maxval)
print('minimum temperature anomaly:', minval)
print('standard deviation:', stdval)
Here we’ve assigned the return value from numpy.max(data) to the variable maxval, the value
from numpy.min(data) to minval, and so on.
maximum temperature anomaly: 1.66
minimum temperature anomaly: -3.75
standard deviation: 0.5596297173782723
Mystery Functions in IPython
How did we know what functions NumPy has and how to use them? If you are working in IPython or in a Jupyter Notebook, there is an easy way to find out. If you type the name of something followed by a dot, then you can use tab completion (e.g. type
numpy.and then press tab) to see a list of all functions and attributes that you can use. After selecting one, you can also add a question mark (e.g.numpy.cumprod?), and IPython will return an explanation of the method! This is the same as doinghelp(numpy.cumprod).
When analyzing data, though, we often want to look at variations in statistical values, such as the maximum monthly temperature anomaly per date or the average temperature anomaly per geographical region. One way to do this is to create a new temporary array of the data we want, then ask it to do the calculation:
T_197812 = data[0, :] # 0 on the first axis (rows), everything on the second (columns)
print('maximum monthly temperature anomaly in December 1978:', numpy.max(T_197812))
maximum monthly temperature anomaly in December 1978: 0.47
Everything in a line of code following the ‘#’ symbol is a comment that is ignored by Python. Comments allow programmers to leave explanatory notes for other programmers or their future selves.
We don’t actually need to store the row in a variable of its own. Instead, we can combine the selection and the function call:
print('maximum monthly temperature anomaly in February 1979:', numpy.max(data[2, :]))
maximum monthly temperature anomaly in February 1979: 0.07
What if we need the maximum monthly anomaly for each date over all geographical areas (as in the next diagram on the left) or the average for each geographical area (as in the diagram on the right)? As the diagram below shows, we want to perform the operation across an axis:
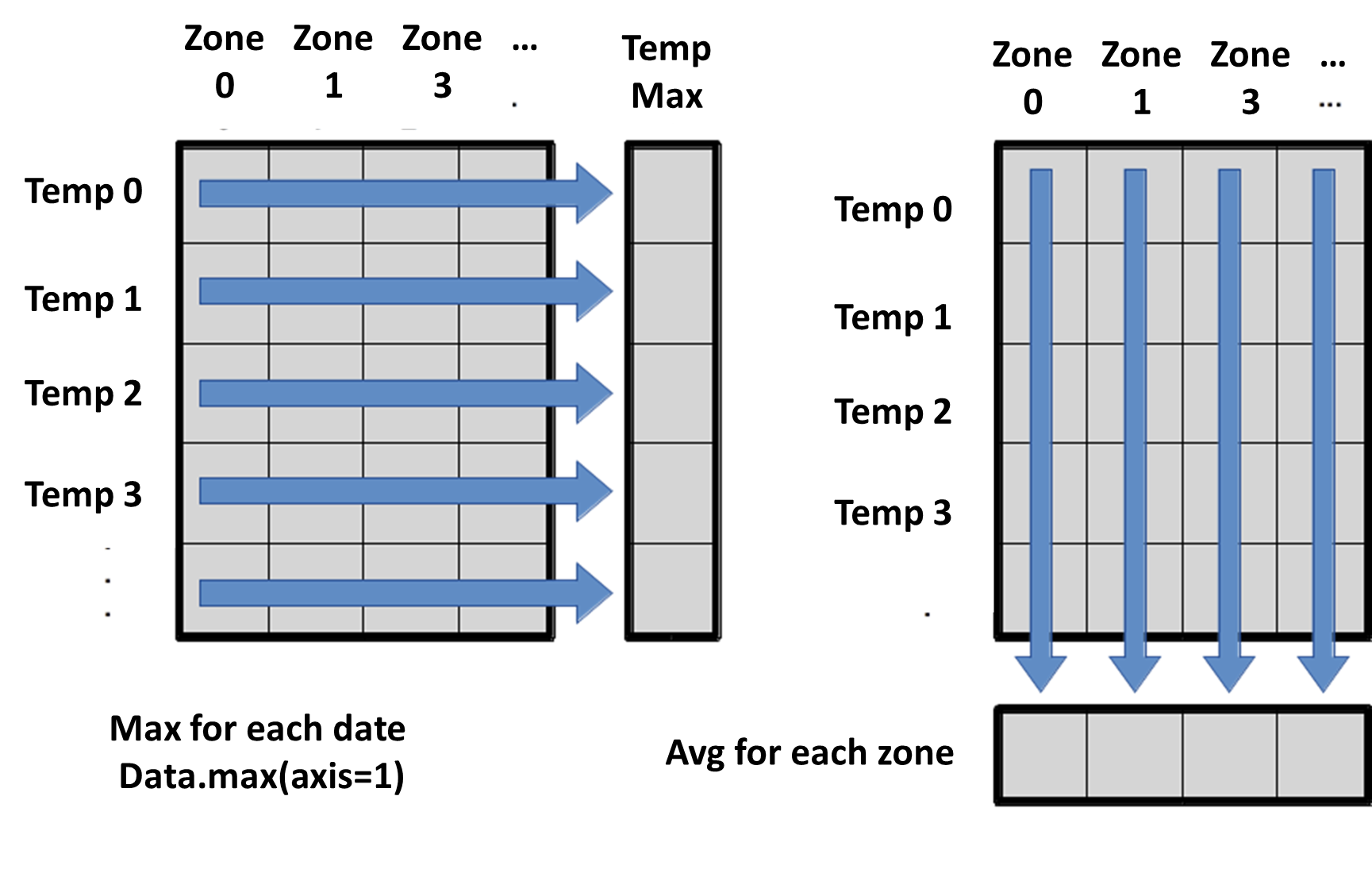
To support this functionality, most array functions allow us to specify the axis we want to work on. If we ask for the average across axis 0 (rows in our 2D example), we get:
print(numpy.mean(data, axis=0))
[-0.17846154 -0.25769231 -0.13307692 -0.23692308 -0.30846154 -0.16615385
-0.12076923 -0.15846154 -0.10769231 -0.02461538 -0.04230769 -0.01615385
-0.35153846 -0.40846154 -0.28153846 -0.16461538 -0.21846154 -0.15076923
-0.78615385 -0.87461538 -0.64692308 -0.20769231 -0.30538462 -0.12846154
-0.75076923 -0.59461538 -0.15692308]
As a quick check, we can ask this array what its shape is:
print(numpy.mean(data, axis=0).shape)
(27,)
The expression (27,) tells us we have an N×1 vector,
so this is the average monthly temperature anomaly per geographical region for all dates.
If we average across axis 1 (columns in our 2D example), we get:
print(numpy.mean(data, axis=1))
[-0.39444444 -0.35851852 -0.71851852 -0.35259259 -0.36481481 -0.37185185
-0.36777778 -0.2637037 -0.37555556 -0.05703704 -0.04962963 -0.23333333
0.16296296]
which is the average temperature anomaly per date across all geographical regions.
Visualizing data
The mathematician Richard Hamming once said, “The purpose of computing is insight, not numbers,” and
the best way to develop insight is often to visualize data. Visualization deserves an entire
lecture of its own, but we can explore a few features of Python’s matplotlib library here. While
there is no official plotting library, matplotlib is the de facto standard. First, we will
import the pyplot module from matplotlib and use two of its functions to create and display a
heat map of our data:
import matplotlib.pyplot
image = matplotlib.pyplot.imshow(data)
matplotlib.pyplot.show()
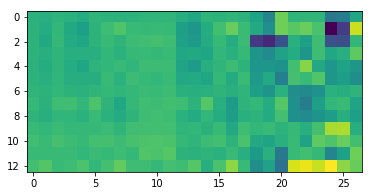
Blue pixels in this heat map represent low values, while yellow pixels represent high values. As we can see, temperature anomalies vary significantly depending on the geographical area.
Some IPython Magic
If you’re using a Jupyter notebook, you’ll need to execute the following command in order for your matplotlib images to appear in the notebook when
show()is called:%matplotlib inlineThe
%indicates an IPython magic function - a function that is only valid within the notebook environment. Note that you only have to execute this function once per notebook.
Let’s take a look at the average temperature over each geographical area:
ave_temp = numpy.mean(data, axis=0)
ave_plot = matplotlib.pyplot.plot(ave_temp)
matplotlib.pyplot.show()
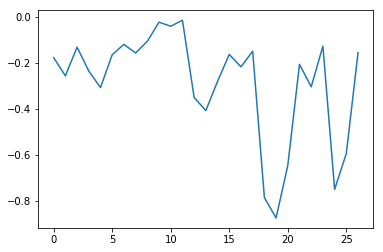
Here, we have put the average per geographical area across all dates in the variable ave_temp, then
asked matplotlib.pyplot to create and display a line graph of those values. The result is a
shows that significant changes appear in the poles, USA and Australia. Let’s have a look at two other statistics:
max_plot = matplotlib.pyplot.plot(numpy.max(data, axis=0))
matplotlib.pyplot.show()
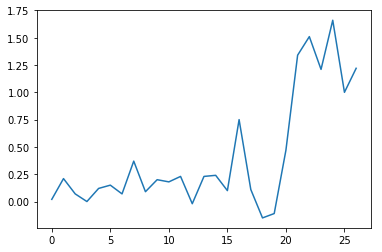
min_plot = matplotlib.pyplot.plot(numpy.min(data, axis=0))
matplotlib.pyplot.show()
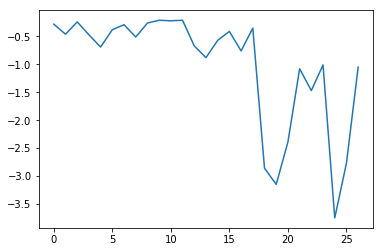
The maximum value is stable and increases quickly, while the minimum is stable and decreases significantly. The first values for both the minimum and maximum concern the entire globe so we can say that for this period the global temperature anomaly is not significant while for some areas there are strong variations. This insight would have been difficult to reach by examining the numbers themselves without visualization tools.
Grouping plots
You can group similar plots in a single figure using subplots.
This script below uses a number of new commands. The function matplotlib.pyplot.figure()
creates a space into which we will place all of our plots. The parameter figsize
tells Python how big to make this space. Each subplot is placed into the figure using
its add_subplot method. The add_subplot method takes 3
parameters. The first denotes how many total rows of subplots there are, the second parameter
refers to the total number of subplot columns, and the final parameter denotes which subplot
your variable is referencing (left-to-right, top-to-bottom). Each subplot is stored in a
different variable (axes1, axes2, axes3). Once a subplot is created, the axes can
be titled using the set_xlabel() command (or set_ylabel()).
Here are our three plots side by side:
import numpy
import matplotlib.pyplot
data = numpy.loadtxt(fname='../data/uahncdc.lt-01.csv', skiprows=1, delimiter=',')
fig = matplotlib.pyplot.figure(figsize=(10.0, 3.0))
axes1 = fig.add_subplot(1, 3, 1)
axes2 = fig.add_subplot(1, 3, 2)
axes3 = fig.add_subplot(1, 3, 3)
axes1.set_ylabel('average')
axes1.plot(numpy.mean(data, axis=0), marker = 'o', linestyle ='-')
axes2.set_ylabel('max')
axes2.plot(numpy.max(data, axis=0), marker = 'o', linestyle ='-')
axes3.set_ylabel('min')
axes3.plot(numpy.min(data, axis=0), marker = 'o', linestyle ='-')
fig.tight_layout()
matplotlib.pyplot.show()
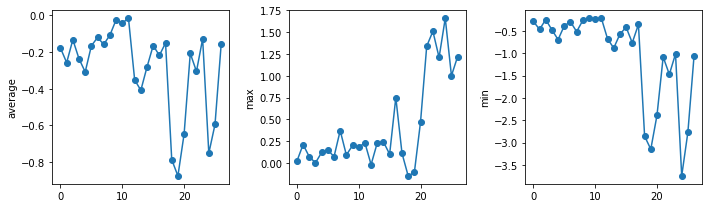
The call to loadtxt reads our data,
and the rest of the program tells the plotting library
how large we want the figure to be,
that we’re creating three subplots,
what to draw for each one,
and that we want a tight layout.
(If we leave out that call to fig.tight_layout(),
the graphs will actually be squeezed together more closely.)
Scientists Dislike Typing
We will always use the syntax
import numpyto import NumPy. However, in order to save typing, it is often suggested to make a shortcut like so:import numpy as np. If you ever see Python code online using a NumPy function withnp(for example,np.loadtxt(...)), it’s because they’ve used this shortcut. When working with other people, it is important to agree on a convention of how common libraries are imported.
Check Your Understanding
What values do the variables
massandagehave after each statement in the following program? Test your answers by executing the commands.mass = 47.5 age = 122 mass = mass * 2.0 age = age - 20 print(mass, age)Solution
95.0 102
Sorting Out References
What does the following program print out?
first, second = 'Grace', 'Hopper' third, fourth = second, first print(third, fourth)Solution
Hopper Grace
Slicing Strings
A section of an array is called a slice. We can take slices of character strings as well:
element = 'oxygen' print('first three characters:', element[0:3]) print('last three characters:', element[3:6])first three characters: oxy last three characters: genWhat is the value of
element[:4]? What aboutelement[4:]? Orelement[:]?Solution
oxyg en oxygenWhat is
element[-1]? What iselement[-2]?Solution
n eGiven those answers, explain what
element[1:-1]does.Solution
Creates a substring from index 1 up to (not including) the final index, effectively removing the first and last letters from ‘oxygen’
Thin Slices
The expression
element[3:3]produces an empty string, i.e., a string that contains no characters. Ifdataholds our array of patient data, what doesdata[3:3, 4:4]produce? What aboutdata[3:3, :]?Solution
[] []
Plot Scaling
Why do all of our plots stop just short of the upper end of our graph?
Solution
Because matplotlib normally sets x and y axes limits to the min and max of our data (depending on data range)
If we want to change this, we can use the
set_ylim(min, max)method of each ‘axes’, for example:axes3.set_ylim(0,6)Update your plotting code to automatically set a more appropriate scale. (Hint: you can make use of the
maxandminmethods to help.)Solution
# One method axes3.set_ylabel('min') axes3.plot(numpy.min(data, axis=0)) axes3.set_ylim(-4,0)Solution
# A more automated approach min_data = numpy.min(data, axis=0) axes3.set_ylabel('min') axes3.plot(min_data, marker = 'o', linestyle ='-') axes3.set_ylim(numpy.min(min_data)*1.1, numpy.max(min_data) * 0.1)
Drawing Straight Lines
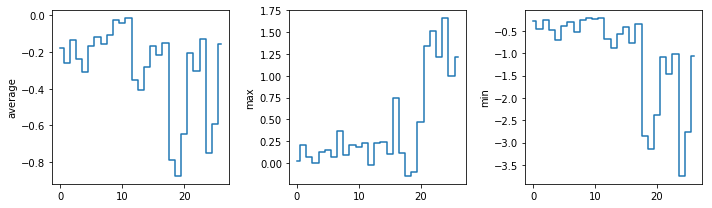
In the center and right subplots above, we expect all lines to look like step functions because non-integer value are not realistic for the minimum and maximum values. However, you can see that the lines are not always vertical or horizontal, and in particular the step function in the subplot on the right looks slanted. Why is this?
Solution
Because matplotlib interpolates (draws a straight line) between the points. One way to do avoid this is to use the Matplotlib
drawstyleoption:import numpy import matplotlib.pyplot data = numpy.loadtxt(fname='../data/uahncdc.lt-01.csv', skiprows=1, delimiter=',') fig = matplotlib.pyplot.figure(figsize=(10.0, 3.0)) axes1 = fig.add_subplot(1, 3, 1) axes2 = fig.add_subplot(1, 3, 2) axes3 = fig.add_subplot(1, 3, 3) axes1.set_ylabel('average') axes1.plot(numpy.mean(data, axis=0), drawstyle='steps-mid') axes2.set_ylabel('max') axes2.plot(numpy.max(data, axis=0), drawstyle='steps-mid') axes3.set_ylabel('min') axes3.plot(numpy.min(data, axis=0), drawstyle='steps-mid') fig.tight_layout() matplotlib.pyplot.show()
Make Your Own Plot
Create a plot showing the standard deviation (
numpy.std) of the temperature anomaly data for each geographical region across all dates.Solution
std_plot = matplotlib.pyplot.plot(numpy.std(data, axis=0), marker = 'o', linestyle ='-') matplotlib.pyplot.show()
Moving Plots Around
Modify the program to display the three plots on top of one another instead of side by side.
Solution
import numpy import matplotlib.pyplot data = numpy.loadtxt(fname='../data/uahncdc.lt-01.csv', skiprows=1, delimiter=',') # change figsize (swap width and height) fig = matplotlib.pyplot.figure(figsize=(13.0, 10.0)) # change add_subplot (swap first two parameters) axes1 = fig.add_subplot(3, 1, 1) axes2 = fig.add_subplot(3, 1, 2) axes3 = fig.add_subplot(3, 1, 3) axes1.set_ylabel('average') axes1.plot(numpy.mean(data, axis=0)) axes2.set_ylabel('max') axes2.plot(numpy.max(data, axis=0)) axes3.set_ylabel('min') axes3.plot(numpy.min(data, axis=0)) fig.tight_layout() matplotlib.pyplot.show()
Stacking Arrays
Arrays can be concatenated and stacked on top of one another, using NumPy’s
vstackandhstackfunctions for vertical and horizontal stacking, respectively.import numpy A = numpy.array([[1,2,3], [4,5,6], [7, 8, 9]]) print('A = ') print(A) B = numpy.hstack([A, A]) print('B = ') print(B) C = numpy.vstack([A, A]) print('C = ') print(C)A = [[1 2 3] [4 5 6] [7 8 9]] B = [[1 2 3 1 2 3] [4 5 6 4 5 6] [7 8 9 7 8 9]] C = [[1 2 3] [4 5 6] [7 8 9] [1 2 3] [4 5 6] [7 8 9]]Write some additional code that slices the first and last columns of
A, and stacks them into a 3x2 array. Make sure toSolution
A ‘gotcha’ with array indexing is that singleton dimensions are dropped by default. That means
A[:, 0]is a one dimensional array, which won’t stack as desired. To preserve singleton dimensions, the index itself can be a slice or array. For example,A[:, :1]returns a two dimensional array with one singleton dimension (i.e. a column vector).D = numpy.hstack((A[:, :1], A[:, -1:])) print('D = ') print(D)D = [[1 3] [4 6] [7 9]]Solution
An alternative way to achieve the same result is to use Numpy’s delete function to remove the second column of A.
D = numpy.delete(A, 1, 1) print('D = ') print(D)D = [[1 3] [4 6] [7 9]]
Change In Temperature anomalies
Each row of the dataset represents a series of observations relating to one geographical region. This means that the change for each geographical area in temperature anomaly over time is a meaningful concept.
The
numpy.diff()function takes a NumPy array and returns the differences between two successive values along a specified axis. For example, a NumPy array that looks like this:npdiff = numpy.array([ 0, 2, 5, 9, 14])Calling
numpy.diff(npdiff)would do the following calculations and put the answers in another array.[ 2 - 0, 5 - 2, 9 - 5, 14 - 9 ]numpy.diff(npdiff)array([2, 3, 4, 5])Which axis would it make sense to use this function along?
Solution
Since the row axis (0) is time, it makes sense to get the difference between two arbitrary dates.
numpy.diff(data, axis=0)The column axis (1) corresponds to different geographical areas so it can also be meaningful to compute the difference between two areas.
If the shape of an individual data file is
(13, 27)(13 rows and 27 columns), what would the shape of the array be after you run thediff()function and why?Solution
The shape will be
(12, 27)because there is one fewer difference between columns than there are columns in the data.How would you find the largest change in temperature anomaly for each geographical area? Does it matter if the change in temperature anomaly is an increase or a decrease?
Solution
By using the
numpy.max()function after you apply thenumpy.diff()function, you will get the largest difference between days.numpy.max(numpy.diff(data, axis=0), axis=0)array([0.14, 0.32, 0.14, 0.26, 0.28, 0.37, 0.23, 0.44, 0.24, 0.12, 0.18, 0.12, 0.29, 0.51, 0.56, 0.39, 0.83, 0.3 , 1.92, 2.01, 1.76, 1.42, 1.57, 1.36, 2.94, 2.14, 1.72])If temperature anomaly values decrease along an axis, then the difference from one element to the next will be negative. If you are interested in the magnitude of the change and not the direction, the
numpy.absolute()function will provide that.Notice the difference if you get the largest absolute difference between readings.
numpy.max(numpy.absolute(numpy.diff(data, axis=0)), axis=0)array([0.14, 0.32, 0.18, 0.26, 0.28, 0.37, 0.23, 0.44, 0.24, 0.22, 0.27, 0.18, 0.3 , 0.51, 0.56, 0.39, 0.83, 0.46, 2.41, 2.12, 2.85, 1.42, 1.57, 1.36, 2.94, 2.14, 1.72])
Key Points
Import a library into a program using
import libraryname.Use the
numpylibrary to work with arrays in Python.Use
variable = valueto assign a value to a variable in order to record it in memory.Variables are created on demand whenever a value is assigned to them.
Use
print(something)to display the value ofsomething.The expression
array.shapegives the shape of an array.Use
array[x, y]to select a single element from a 2D array.Array indices start at 0, not 1.
Use
low:highto specify aslicethat includes the indices fromlowtohigh-1.All the indexing and slicing that works on arrays also works on strings.
Use
# some kind of explanationto add comments to programs.Use
numpy.mean(array),numpy.max(array), andnumpy.min(array)to calculate simple statistics.Use
numpy.mean(array, axis=0)ornumpy.mean(array, axis=1)to calculate statistics across the specified axis.Use the
pyplotlibrary frommatplotlibfor creating simple visualizations.